
Deep Blending for Free-Viewpoint
Image-Based-Rendering
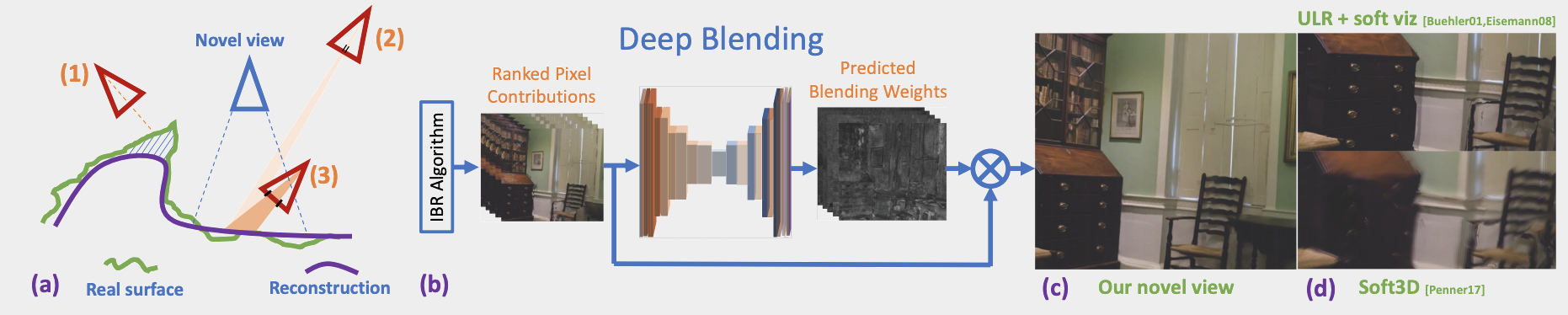 |
| Image-based rendering blends contributions from different input images to synthesize a novel view. (a) This blending operation is complex for a variety of reasons. For example, incorrect visibility (e.g., for the non-reconstructed green surface in input view (1)) may result in wrong projections of an image into the novel view. Blending must also account for, e.g., differences in projected resolution ((2) and (3)). Previous methods have used hand-crafted heuristics to overcome these issues. (b) Our method generates a set of ranked contributions (mosaics) from the input images and uses predicted blending weights from a CNN to perform deep blending and synthesize (c) novel views. Our solution significantly reduces visible artifacts compared to (d) previous methods. |
Abstract
Free-viewpoint image-based rendering (IBR) is a standing challenge. IBR methods combine warped versions of input photos to synthesize a novel view. The image quality of this combination is directly affected by geometric inaccuracies of multi-view stereo (MVS) reconstruction and by view- and image-dependent effects that produce artifacts when contributions from different input views are blended. We present a new deep learning approach to blending for IBR, in which we use held-out real image data to learn blending weights to combine input photo contributions. Our Deep Blending method requires us to address several challenges to achieve our goal of interactive free-viewpoint IBR navigation. We first need to provide sufficiently accurate geometry so the Convolutional Neural Network (CNN) can succeed in finding correct blending weights. We do this by combining two different MVS reconstructions with complementary accuracy vs. completeness tradeoffs. To tightly integrate learning in an interactive IBR system, we need to adapt our rendering algorithm to produce a fixed number of input layers that can then be blended by the CNN. We generate training data with a variety of captured scenes, using each input photo as ground truth in a held-out approach. We also design the network architecture and the training loss to provide high quality novel view synthesis, while reducing temporal flickering artifacts. Our results demonstrate free-viewpoint IBR in a wide variety of scenes, clearly surpassing previous methods in visual quality, especially when moving far from the input cameras.
 Paper PDF (90.1 MB)
Paper PDF (90.1 MB)
 Supplemental material
Supplemental material
 Network code
Network code
BibTeX
@article{DeepBlending2018,
author = {Hedman, Peter and Philip, Julien and Price, True and Frahm, Jan-Michael and Drettakis, George and Brostow, Gabriel},
title = {Deep Blending for Free-viewpoint Image-based Rendering},
booktitle = {ACM Transactions on Graphics (Proc. SIGGRAPH Asia)},
publisher = {ACM},
volume = {37},
number = {6},
pages = {257:1--257:15},
year = {2018}
}
Acknowledgements
This research was financially supported by the Rabin Ezra scholarship fund, NSF CNS-1405847, NERC NE/P019013/1, and the EU H2020 EMOTIVE project. We thank Clément Godard for helpful input on network training and different loss functions, Akash Bapat for conversations regarding depthmap and global geometry improvements, and Adrien Bousseau for insightful comments.