
Interactive Sketching of Mannequin Poses
3DV 2022
Abstract
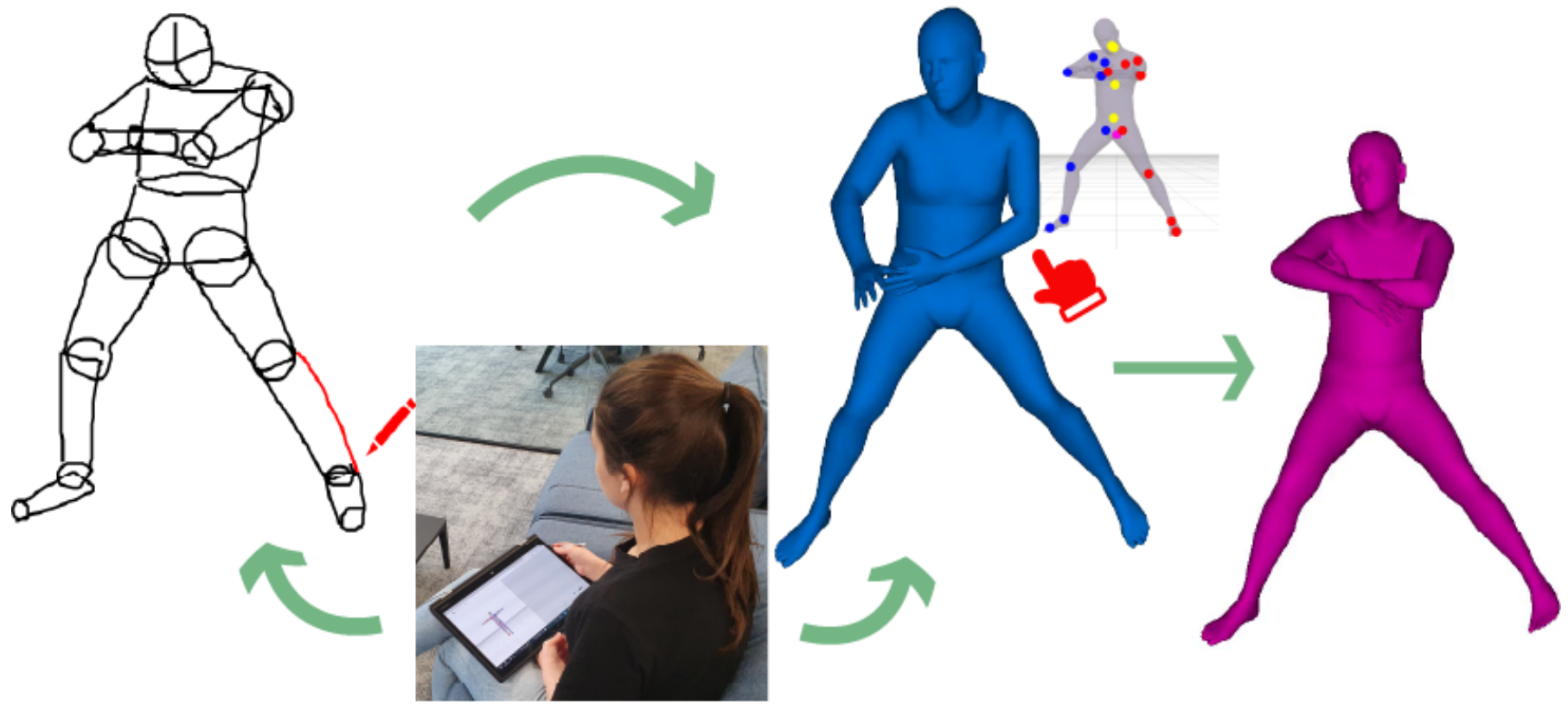
It can be easy and even fun to sketch humans in different poses. In contrast, creating those same poses on a 3D graphics ``mannequin'' is comparatively tedious. Yet 3D body poses are necessary for various downstream applications. We seek to preserve the convenience of 2D sketching while giving users of different skill levels the flexibility to accurately and more quickly pose\slash refine a 3D mannequin.
At the core of the interactive system, we propose a machine-learning model for inferring the 3D pose of a CG mannequin from sketches of humans drawn in a cylinder-person style. Training such a model is challenging because of artist variability, a lack of sketch training data with corresponding ground truth 3D poses, and the high dimensionality of human pose-space. Our unique approach to synthesizing vector graphics training data underpins our integrated ML-and-kinematics system. We validate the system by tightly coupling it with a user interface, and by performing a user study, in addition to quantitative comparisons.


BibTeX
@InProceedings{unlu2022interactive,
author = {Unlu, Gizem Esra and Sayed, Mohamed and Brostow, Gabriel},
title = {Interactive Sketching of Mannequin Poses},
booktitle = {Proceedings of the IEEE/CVF International Conference on 3D Vision (3DV)},
month = {September},
year = {2022}
}