Becoming the Expert -
Interactive Multi-Class Machine Teaching
Can a Computer Teach a Human?
Compared to machines, humans are extremely good at classifying images into categories, especially when they possess prior knowledge of the categories at hand. If this prior information is not available, supervision in the form of teaching images is required. To learn categories more quickly, people should see important and representative images first, followed by less important images later - or not at all. However, image-importance is individual-specific, i.e. a teaching image is important to a student if it changes their overall ability to discriminate between classes. Further, students keep learning, so while image-importance depends on their current knowledge, it also varies with time.
In this work we propose an Interactive Machine Teaching algorithm that enables a computer to teach challenging visual concepts to a human. Our adaptive algorithm chooses, online, which labeled images from a teaching set should be shown to the student as they learn. We show that a teaching strategy that probabilistically models the student's ability and progress, based on their correct and incorrect answers, produces better `experts'. We present results using real human participants across several varied and challenging real-world datasets.
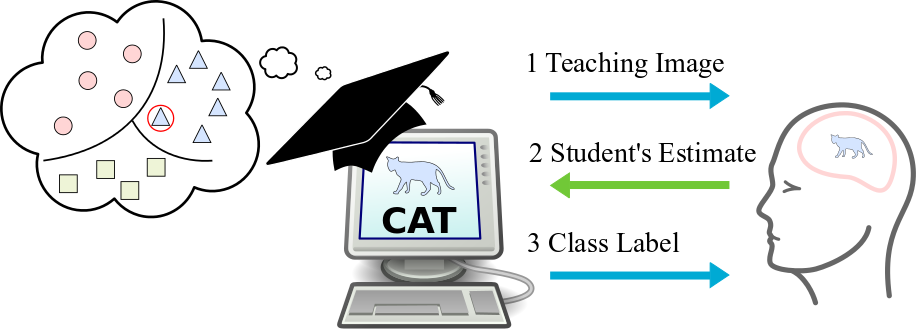
Interactive Machine Teaching
In our Interactive Machine Teaching setup, the teaching algorithm’s goal is to teach a human learner a new visual classification task, one that the human is not already familiar with. The only interaction the teacher can have with the student is to show them single example images from a teaching set. The teaching set is collection of images with corresponding ground truth class labels. During each round of teaching the teacher shows an image to the student, waits for the student’s estimate of the class label, updates their model of the student’s knowledge, and finally reveals the correct class label for the image. To choose the next teaching image to show, the teacher makes use of the knowledge they have garnered from the student during the previous rounds of teaching. This loop proceeds until teaching is finished.
Datasets
To evaluate the effectiveness of our teaching strategy we performed experiments using four different datasets each containing several hundred images. Example images can be seen below, where each column shows three random images per class. Note, that the Seabed images are particularly difficult to categorize as they as they were captured ’in the wild’ and as a result contain occlusion, clutter, and large amounts of intra-class variation.

Results
We recruited participants using Mechanical Turk. Each participant was presented with a random dataset and one of five different teaching strategies. They first underwent several rounds of teaching, as described above, followed by a testing phase. The testing phase is similar to teaching with the only difference being that the students did not receive any feedback regarding the true class label after each image was presented to them. Below, we present the average test results (higher numbers are better) across all participants for each of the different datasets. Compared to the other baselines, our EER teaching strategy (in red) tends to produce students who exhibit better classification performance on average during testing. For more details please see our paper.

Publications
Data and Code
Images and decriptors (122Mb): Data
Python code (114Mb): Code
Demo: live demo
Acknowledgements
Funding for this research was provided by EPSRC grant EP/K015664/1 and by Sustainable Fisheries Greenland. We would like to thank Maciej Gryka for his web development advice and the NHM London for providing the butterfly data. Edward Johns' funding was provided by the Greenland Benthic Assessment project at the Institute of Zoology, ZSL, in association with the Greenland Institute of Natural Resources.
Contact: o.macaodha (@) cs.ucl.ac.uk
|

